
(原标题:从文本到图像和声音:科大讯飞星火V3.5更新发布,打破大模型的信息获取界限)
4月26日,科大讯飞发布了V3.5版本的更新,宣布讯飞星火成为业界首个支持长文本、长图文以及长语音的大模型产品。作为人工智能国家队的一员,科大讯飞此次升级的讯飞星火V3.5旨在解决用户在高效准确获取知识方面的痛点。与行业其他产品相比,讯飞星火不仅支持长文本,还加入了长图文和长语音功能,拓宽了大模型在多媒体资料获取和理解方面的能力。
长文本已经成为国产大模型用户关注的新方向。国内大模型创业公司月之暗面去年将旗下的大模型Kimi的上下文参数规模提升至20万字,上个月又提升至200万,迅速引爆市场。3月,阿里旗下的通义千问已经将这一数字更新到1000万,宣称是“全球文档处理容量第一的AI应用”。华泰证券在一份研报中指出,具有长上下文的大模型通用性更强,用户将特定领域的知识通过上下文的方式输入到模型中,模型即可通过上下文学习掌握相应内容,一定程度上代替模型的微调。

图片来源于网络,如有侵权,请联系删除
然而,经过几个月的比拼跟进之后,长文本之于大模型似乎又成了一项厂家炫技的同质化环节,以至于有媒体已经飞快地喊出了“长文本降温”的口号,长文本如何才能真正落地陷入瓶颈。
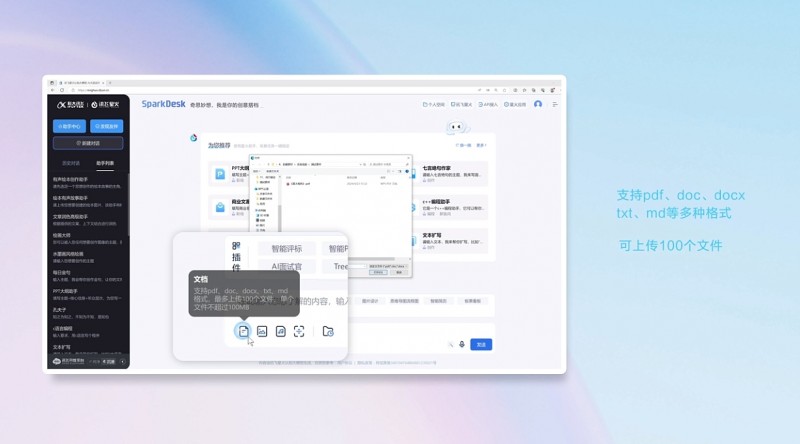
大模型长文本功能的落地需要重点解决两个问题。一是海量文本的高效处理。面对上百万甚至上千万文字,模型后台消耗的运算资源也成倍增加,业界的一些大模型往往智能处理前20%或前50%的内容,之后的处理效率就大大减慢。二是如何保证大模型在科研、医疗、法律等行业专业场景的准确率,这样才能解决大模型在刚需场景的应用问题。
为了解决大模型应用效率和准确率问题,讯飞星火V3.5提升了对长文本的理解、学习、回答能力,并进行了重要的模型剪枝和蒸馏,从而推出业界最优的130亿参数的大模型。在效果损失仅3%以内的情况下,使得星火在文档上传解析、知识问答的首响时间以及文字生成效率方面都获得了极大的效率提升。
除了长文本,科大讯飞还加入了长图文和长语音功能。图文识别一直是多语言大模型的难点之一。为了解决这一痛点,科大讯飞在多年深耕图文识别的基础上,首发星火图文识别大模型,覆盖了书籍、学术论文、报纸、体检报告、PPT等31个工作生活中的常见场景,并针对最常见的18种板面要素进行优化。
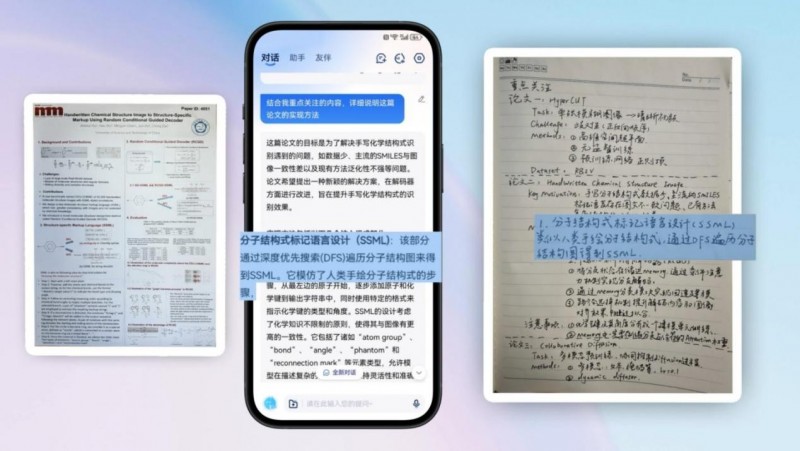
在此次升级中,面对广泛的音视频信息高效获取需求,科大讯飞也推出长语音功能,将国际领先的语音识别和翻译技术结合起来,可以实现会议录音、学习视频等的一键研读,实现音视频场景的高效知识获取。
总的来说,科大讯飞通过讯飞星火V3.5的发布展示了其在人工智能领域的领先地位和技术实力。长图文和长语音的加入为大模型的长文本玩法扩充了更多的想象空间,使得大模型可以获取的资料不再仅局限于文本内容,视觉、听觉也成为大模型的信息获取来源。这将为科大讯飞在人工智能领域的发展带来更多的机会和可能性。
本文来源:财经报道网
推荐阅读:
“牛市旗手”冲高回落,红塔证券尾盘炸板,市场人士:市场正常调整
快手发布《2024老铁春节团购消费数据报告》,170万老铁成为品牌商家新客户
龙年A股开门红提振信心 坤元资产FOF伙伴加速孵化新质生产力
专题推荐: