
人工智能从理论走向应用的脚步加快。随着技术不断演进,我们迎来了更加智能化的时代,人工智能在各个领域都呈现出日益增长的影响力。
图片来源于网络,如有侵权,请联系删除
2024年,进化之路上AI将有怎样的颠覆性突破?其应用场景、商业模式的迭代和革新会给人类带来危机还是新机?
图片来源于网络,如有侵权,请联系删除
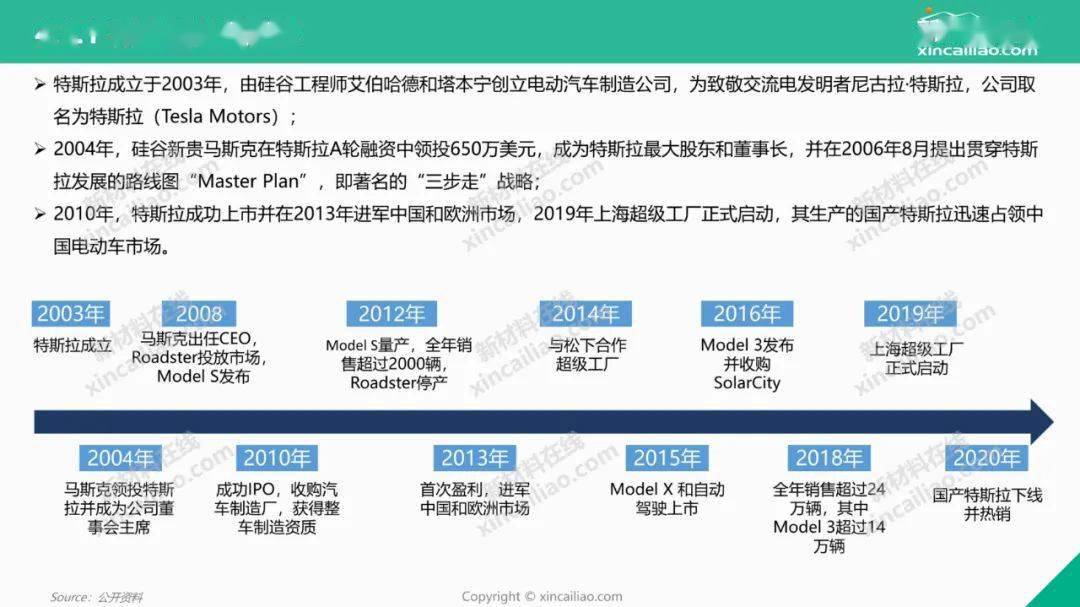
1月28日,南财合规科技研究院与中国社科院法学所网络与信息法研究室共同发布《2024年十大AI趋势预测》,研究团队结合2023年全球的人工智能发展、应用情况,试图从技术、商业以及治理的维度对行业发展做出预测。该预测在中国社会科学院法学研究所主办的“人工智能安全治理研讨会”暨中国社会科学院“人工智能安全治理研究”实验室孵化研讨会上发布。
图片来源于网络,如有侵权,请联系删除
2024年十大AI趋势为:
1、开源模型性能日益强大,有望与闭源模型分庭抗礼
2、AI Agent快速崛起,助力大模型应用落地
3、多模态大模型成为AI产业竞争重要阵地
4、AI应用场景爆发,“AI+”实践补齐商业化短板
5、具身智能,通用人工智能探索的下一节点
6、高质量数据稀缺,合成数据或成解法
7、新型智算中心、数据中心加快布局 成为关键基础设施
8、人工智能版权纠纷大量涌入司法实践
9、一批AI创业公司在2024年倒闭
10、安全可信AI诉求催生新技术、新商业工具
一、开源模型性能日益强大,有望与闭源模型分庭抗礼
以GPT-4为代表的闭源大模型在2023年展现了出众能力,福布斯预测2024年商业闭源大模型仍将持续领先于开源大模型。
开源代表Yann LeCun(Meta首席AI科学家)、Clem Delangue(Hugging Face CEO)等看好开源大模型的发展,认为开源大模型能够达到或超越闭源大模型的能力。
自Llama 2后,开源又逐渐成为主流趋势,2023年底,Meta和IBM宣布共同成立了一个人工智能联盟,由50多家人工智能公司和研究机构组成,旨在培养开放社区。国内阿里、百川等也在做开源部署。受益于科技公司的资源投入以及全球开源社区的共享协作,开源大模型在速度、适应性以及整体效率方面都有望持续提升。
闭源大模型被视为具有较高的安全性,能够发挥其保护数据隐私或商业利益的作用,并且能够将专业力量持续投入到与业务场景的融合中,具备长期服务能力。比如OpenAI也会推出定制化GPT、应用商店等构建以ChatGPT为基础的闭源模型生态体系。
未来,开源与闭源模型之争的走向会如何,是互为补充并服务于不同的场景及需求,还是一方碾压另一方,市场会告诉我们答案。
二、AI Agent快速崛起,助力大模型应用落地
AI Agent是一个控制大模型来解决问题的代理系统,可以理解为大模型、记忆、任务规划以及工具使用的集合,能够根据给定任务详细拆解出每一步的计划步骤,依靠外界反馈和自主思考,为自己创建prompt以实现目标。
比尔及梅琳达·盖茨基金会联席主席比尔·盖茨预计AI Agent会改变人类与计算机的交互方式,带来从输入命令到点击图标的计算革命,并将在医疗保健、教育、生产力以及娱乐和购物四个领域产生重要影响。知名科学家李飞飞认为AI Agent作为一种辅助智能体,能够比完全自动化更早实现。DeepLearning.AI创始人吴恩达则期待在2024年AI Agent将会有新的突破。
从单一Agent发展到多个Agent协调合作,AI Agent可以通过将复杂任务拆解为多个子任务的分工,突破特定领域或场景限制,节约不同流程之间的切换时间,同时不断提升处理特定任务的技能,提高整个系统的效率和产出质量。
在商业化力量的推动下,AI Agent可能会成为大模型落地业务场景的重要载体,例如帮助企业更加高效便捷地自己构建RPA、CRM、办公OA等一系列应用,帮助个人规划和执行一系列动作等。2024年,在AI Agent的代理下,大模型将为我们执行更多任务。
三、多模态大模型成为AI产业竞争的重要阵地
人类通过视觉、语言、听觉等感知与理解真实世界,AI作为人类智能的延伸也在拓展多模态能力,包括多模态的输入和多模态的输出与生成能力。多模态大模型可以处理应用文字、图片、视频、音频等多模态数据,完成听、说、读、写、看等跨模态领域的任务,符合人类最自然的交互习惯,使人与AI的交流更加友好直接。
火爆海外的AI视频生成工具Pika1.0,其AI模型能生成和编辑 3D 动画、电影等各种风格视频。谷歌在2023年年底推出的Gemini模型则能够分析和理解正在变化的视频,并生成相应的描述,描述的音频还会包含一些拟人化的语气和停顿。国内方面,2024年1月以来,通义千问视觉理解模型Qwen-VL持续升级,零一万物Yi-VL多模态语言大模型面向全球开源,多模态模型的能力正在快速提升。
由于多模态能够带来更丰富的用户体验、实现更广泛的应用场景,2024年多模态大模型将成为AI厂商发力的主要方向,多模态大模型正推动人工智能迈进“通感”时代。
四、AI应用场景爆发,“AI+”实践补齐商业化短板
2023至2024,AI赋能千行百业脚步走深。赛迪顾问数据显示,2023 年人工智能在行业应用的采用率已达到 28%。从行业实践来看,人工智能率先助力金融、游戏、教育、医疗等行业重构。
人工智能必须与应用场景结合才能发挥最大作用。在诞生至今的60余年间,其发展几次起落,应用场景不足被视为前两次浪潮归于沉寂的主要原因之一。
人工智能面向行业的具体应用并非易事,需要把技术逻辑、业务逻辑、场景逻辑和商业逻辑打通。2024年被视为人工智能应用元年,场景创新、应用落地、商业化拓展值得期待。在这条追求更高精度、挑战更复杂任务、拓展能力边界的演进之路上,从业者需着眼产业链全局布局场景建设,让AI技术革新惠及整个产业生态。
五、具身智能,通用人工智能探索的下一节点
具身智能(Embodied AI)可以被认为是指能与环境交互获取信息、理解问题、作出决策并实现行动的智能系统。在ITF World 2023大会上,英伟达创始人黄仁勋公开表示,具身智能将引领人工智能的下一次浪潮。
机器人被认为是具身智能落地的核心场景之一。图灵奖得主、中国科学院院士姚期智在此前表示,人工智能领域下一个挑战将是实现“具身通用人工智能”,即构建能够通过自我学习掌握各种技能并执行现实生活中的种种通用任务的高端机器人。
2023年,AI风起,亦卷动具身智能市场风云。特斯拉人形机器人Optimus迭代加速,商业化持续推进。OpenAI领投人形机器人公司1X,二者或共同为机器人开发AI模型。
大语言模型和多模态大模型能够通过海量数据预训练从语音、视觉、感知、控制等多方面帮助机器人更好“进化”。比如,李飞飞团队发布具身智能研究VoxPoser,通过接入大模型,这一项目使机器人能直接理解人类自然语言指令并完成复杂任务,无需额外的数据和预训练。
具身智能可能成为大模型应用元年的“高光时刻”之一。
不过,具身智能走向实践,还面临不少挑战。
在2023世界机器人大会上,姚期智指出,未来具身机器人还面临四大主要挑战:第一,机器人无法只通过一个基础大模型直接做最底层的控制,工作相对复杂;第二,即使谷歌研发了Robotics Transformer模型,要实现实际控制,仍需要弥合计算能力的差距;第三,机器人多模态的感官感知的全部融合并非易事;第四,机器人研发、应用等过程中的数据安全问题需要考虑。
六、高质量数据稀缺,合成数据或成解法
作为生成式人工智能的“粮食和血液”,当前高质量数据的供给面临挑战。一项来自Epoch Al Research团队的研究结果表明,高质量的语言数据存量将在2026年耗尽。
对于数据稀缺问题,合成数据或是一个解法。合成数据是指基于计算机模拟技术或算法生成的虚拟数据。国内外企业目前在这一领域已经开展不少尝试。比如,腾讯开发自动驾驶仿真系统TADSim可以自动生成无需标注的各种交通场景数据;人工智能初创公司Cohere首席执行官AidenGomez就曾公开表示,微软、OpenAI和Cohere等公司,已使用合成数据来训练AI模型。
据咨询公司Gartner预测,到2030年,合成数据将彻底取代真实数据,成为AI模型所使用的数据的主要来源。美国AI研究机构Cognilytica数据显示,2021 年合成数据市场规模大概在1.1亿美元,到2027 年将达到11.5亿美元。
不过,当前合成数据的保真度、可控性等仍存问题。AI训练数据服务商Appen发布的一篇文章中指出,相比于真实数据,合成数据缺乏异常值,这对训练出的模型精确度会产生很大影响。此外,合成数据的质量与其生成时所用的输入数据息息相关,因此,输入数据的质量也会对其产生影响。所以,合成数据投入使用的过程还面临一定争议。
因此,合成数据之外,提升真实数据质量也是必行之措。
在国内,多地都曾发布相关政策以求推动建立高质量数据集。2023年,北京、深圳等地先后发布相关文件,指出要提升高质量数据要素供给能力、归集高质量基础训练数据集、建立多模态公共数据集,打造高质量中文语料数据等。同年7月的《生成式人工智能服务管理暂行办法》中,亦指出要推动生成式人工智能基础设施和公共训练数据资源平台建设。今年国家数据局等17部门联合印发的《“数据要素×”三年行动计划(2024—2026年)》指出,应该建设高质量语料库和基础科学数据集,支持开展人工智能大模型开发和训练。
七、新型智算中心、数据中心加快布局 成为关键基础设施
大模型的发展提升了智能算力的需求,目前国内存在高性能芯片短缺、算力资源分散、存力相对不足等问题。需求爆发式增长与算力单点性能极限之间的矛盾日益突出,算力节点通过网络灵活高效调配算力资源的能力仍存在不足,算网协同和全局调度能力有待提高,难以满足数据对算力随需处理的需求。
因此,需以系统化思维构建算力基础设施平台,保障算力调度,将分散的算力资源聚合,形成集群效应,实现算力、数据和算法的高效协同,满足智算应用场景的数据处理、存储、传输等环节要求。
2023年10月,工信部等六部门联合印发《算力基础设施高质量发展行动计划》,其中提出2025年建成50个智能计算中心等量化指标。2024年1月工信部等八部门发布《关于加快传统制造业转型升级的指导意见》,提出要探索建设区域人工智能数据处理中心,提供海量数据处理、生成式人工智能工具开发等服务。
接下来,新型数据中心、智算中心的建设和布局是一个重要趋势,提供多样性计算综合能力的算力集群,以满足千行百业智能化的需求。
八、人工智能版权纠纷大量涌入司法实践
生成式人工智能技术的快速发展给版权带来了新的挑战。
从输入端看,涉及训练数据来源合法合规问题。大模型训练数据多来自网络中抓取的电子书、艺术作品、电子邮件、歌曲,抓取时并未告知原作者,难以获得单独授权,面临侵权纠纷。
在输出端,终端用户、模型提供者的生成内容是否具有可版权性,模型提供者生成内容是否侵权也未有答案。传统的版权法主要针对人类创作者的作品进行保护,而现在则涉及机器生成的内容。
目前司法实践中,纽约时报指控OpenAI和微软训练大模型使用《纽约时报》大量文本内容侵犯其版权,是输入端的一个案例。
北京互联网法院也作出了第一例人工智能生成内容的著作权纠纷判决,是输出端的一个案例。
2024年,伴随着人工智能技术的不断应用,大概率会有大量版权纠纷案件涌入司法实务环节。
九、一批AI创业公司会在2024年倒闭
2023年人工智能领域资本市场火热。IDC最新数据显示,2022年全球人工智能IT总投资规模为1,288亿美元,2027年预计增至4236亿美元,五年复合增长率(CAGR)约为26.9%。
截至2023年12月末,涉及人工智能产业链的境内A股上市公司已超过400家,业务领域上涵盖了人工智能产业链的各个环节。科创板已汇聚十家人工智能产业链企业,合计市值逾4000亿元,初步覆盖基础层、技术层及应用层等环节,涵盖AI芯片、行业大模型、智能机器人、计算机与3D视觉等多个细分赛道。
不过,从海外来看,AI初创公司融资速度正在放缓,Stability AI 和 Jasper 等初创公司都陷入困境。
2024年人工智能创业公司面临多重挑战。
市场竞争方面,大型公司凭借其资源和品牌优势占据大部分市场份额,使得许多初创AI企业难以立足。资金和融资方面,前期大把烧钱却没有实际商业化落地,融资会变得越发困难。尤其是商业化和产品落地是最大的挑战,如果产品与实际业务场景结合不够紧密,商业化进程受阻。
此外,还面临法律政策的适应性问题,全球各国、地区监管动态密集,不确定性强。数据隐私和安全合规作为底线,可能增加成本。
十、安全可信AI诉求催生新技术、新商业工具
Gartner预测,生成式AI或将迎来全民化时代,到2026年,将有超过80%的企业使用生成式AI的API或模型,或在生产环境中部署支持生成式AI的应用,而在2023年初这一比例还不到5%。
伴随着人工智能的大规模应用,安全问题变得更加迫切。2023年以来,生成式人工智能快速发展的同时,数据泄露、个人隐私风险、虚假信息、大模型“幻觉”、算法黑箱……等问题也随之而来。2023年11月,OpenAI的宫斗大戏把安全对齐、科技伦理等深层安全问题暴露在大众视野中。
人工智能的安全问题可分为三个维度,第一是内生风险,包括“幻觉”问题、算法歧视、算法黑箱等,第二是衍生风险,其在应用中的风险,比如虚假新闻、个人信息泄露等,第三则是外部风险,外部对模型、系统的攻击。
面对多重风险,构建安全可信的人工智能已成为共识。未来在解决AI风险的过程中,可能会催生出针对安全对齐、可解释性等新技术。
此外,针对人工智能内生安全风险、服务商风险、应用产生的数据泄露风险等多维度安全风险,或也会催生新型的商业工具。此前,一家知名保险公司宣布推出专为AI幻觉设计的保险政策。
解决人工智能安全风险是底线,在对安全刚性要求的背景下,或能催生新的安全技术或者商业工具。
推荐阅读:
盘前有料丨证监会重要部署!着力稳市场、稳信心……重要消息还有这些
【25日资金路线图】两市主力资金净流入181亿元 电子等行业实现净流入
专题推荐: